System design 2
Continued from ML system design Part 1. In previous post we discussed about setting up business and ML objectives and also the first two requirements of ML systems Reliability and Scalability. In this post we will discuss the next two requirements.
Maintainability
In the development and maintenance of an ML system, various professionals such as ML engineers, DevOps engineers, and subject matter experts (SMEs) are involved. These individuals often come from diverse backgrounds, utilize different programming languages, and use a variety of tools, each managing distinct parts of the process.
To ensure seamless collaboration, it is crucial to structure workloads and configure the infrastructure so that each contributor can use the tools they are familiar with, rather than imposing a uniform set of tools on everyone. Comprehensive documentation of code is essential, along with versioning for code, data, and artifacts. Models need to be reproducible enough that even in the absence of the original creators, other contributors can understand and build upon the work. When issues arise, the system should support collaborative problem-solving, enabling contributors to identify and resolve issues together.
The Vital Role of SMEs in ML Systems
Subject matter experts (SMEs) are often overlooked in the design of ML systems. However, these systems heavily rely on their expertise and insights. SMEs are not just users; they are integral developers of ML systems.
Typically, SMEs are associated with the data labeling phase, such as when trained professionals identify cancer signs in CT scans. However, as ML model training becomes a continuous process in production, labeling and relabeling also become ongoing tasks throughout the project lifecycle. Involving SMEs beyond the initial labeling phase can significantly enhance an ML system. Their expertise is crucial in areas such as problem formulation, feature engineering, error analysis, model evaluation, reranking predictions, and designing user interfaces to effectively present results to users and other system components.
There are two approaches to solve the problem of maintainability:
Approach 1: Data scientists own the entire process
Approach 2: Have a separate team to manage production
Adaptability
To remain effective amid shifting data distributions and evolving business requirements, an ML system must be capable of identifying areas for performance improvement and implementing updates without interrupting service.
Given that ML systems are composed of both code and data — and data can change rapidly — these systems must be designed to evolve swiftly. This adaptability is closely linked to maintainability.
Iterative process of ML model development
ML system development for production is a highly iterative process and in most cases a never ending cycle. Once a system is put into production, it’ll need to be continually monitored and updated.
For example, here is one workflow that you might encounter when building an ML model to predict the risk of heart failure in a patient:
1. Choose a metric to optimize: For instance, you might want to optimize for the accuracy of predicting heart failure within the next year.
2. Collect data and obtain labels: Gather patient data, including medical history, test results, and whether they experienced heart failure within the specified time frame.
3. Engineer features: Extract relevant features from the data, such as age, cholesterol levels, blood pressure, and lifestyle factors.
4. Train models: Use the prepared data to train your ML model.
5. Error analysis: During error analysis, you realize that errors are caused by incorrect labels, so you relabel the data.
6. Train the model again: Retrain the model with the updated labels.
7. Error analysis: You notice that the model always predicts that patients will not have heart failure because 99.99% of the data consists of patients who did not experience heart failure. Thus, you need to collect more data from patients who did experience heart failure.
8. Train the model again: With a more balanced dataset, retrain the model.
9. Evaluate the model: The model performs well on your existing test data, which is now two months old. However, it performs poorly on recent data from yesterday. Your model is now stale, so you need to update it with more recent data.
10. Train the model again: Retrain the model with the updated dataset.
11. Deploy the model: Put the model into production.
12. Monitor performance: The model seems to be performing well, but then the healthcare providers notice an issue: while predictions are accurate, they are not actionable. Patients are not receiving the necessary interventions in time. So you decide to adjust your model to optimize for early intervention rather than just accuracy.
13. Go to step 1: Restart the process with the new goal of optimizing for early intervention.
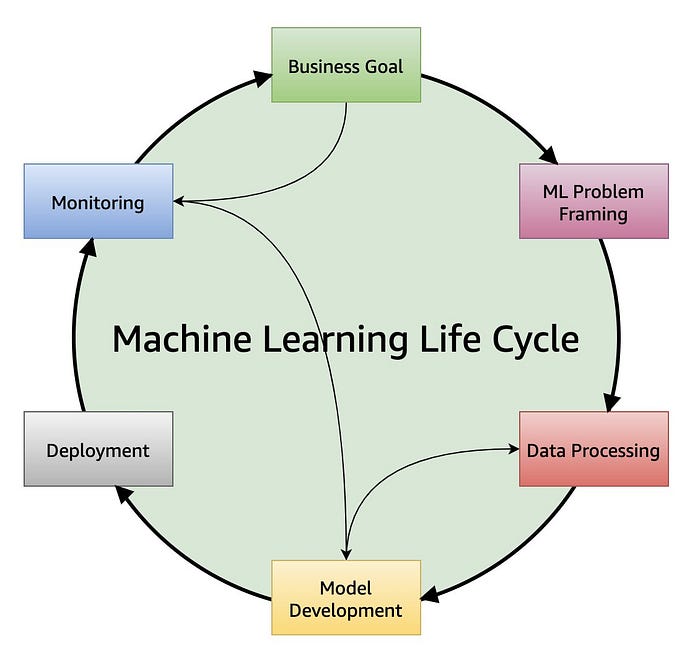
Figure above shows an oversimplified representation of what the iterative process for developing ML systems in production looks like from the perspective of a data scientist or an ML engineer.
Summary:
In this blog post, we explored the essentials of ML systems design and the key considerations involved. Every ML project should begin with a clear understanding of its purpose, driven by specific business objectives that are translated into ML goals to guide model development.
Before starting, it’s crucial to identify the requirements that the ML system must meet, which vary by use case. We focused on four general requirements: reliability, scalability, maintainability, and adaptability.
Building an ML system is not a one-time task but an iterative process that evolves over time.

Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Reading your article helped me a lot and I agree with you. But I still have some doubts, can you clarify for me? I’ll keep an eye out for your answers.