What’s in store for the future of data engineering? In this article, I share some of my topline predictions for 2023 — and beyond.
End of the year prediction articles are hokey, but they serve a purpose. They help us rise above the daily grind and consider where to place our longer term bets.
Next for Data Engineering in 2023?

They also tend to be an exercise in humility as we try to paint a coherent “big picture” of an industry that is rapidly evolving in multiple directions. I challenge anyone to find an industry where more is required of its practitioners to stay current.
These possible directions take on even more meaning as data organizations assess — and reassess — their priorities in light of a looming recession, and your data engineering investments can make or break your company’s ability to stay nimble, innovative, and competitive.
The good news? Necessity is the mother of invention, and I predict that 2023 will be a banner year for technologies that help teams save time, revenue, and resources on DataOps so engineers can focus on building, scaling, and generally doing more with less.
Here are my predictions for some of the most important trends heading into next year (in no particular order).
Prediction #1: Data Engineering Teams Will Spend More Time On FinOps / Data Cloud Cost Optimization
As more data workloads move to the cloud, I foresee that data will become a larger portion of a company’s spend and draw more scrutiny from finance.
It’s no secret that the macro economic environment is starting to transition from a period of rapid growth and revenue acquisition to a more restrained focus on optimizing operations and profitability. We’re seeing more financial officers play increasing roles in deals with data teams and it stands to reason this partnership will also include recurring costs as well.
Data teams will still need to primarily add value to the business by acting as a force multiplier on the efficiency of other teams and by increasing revenue through data monetization, but cost optimization will become an increasingly important third avenue.
This is an area where best practices are still very nascent as data engineering teams have focused on speed and agility to meet the extraordinary demands placed on them. Most of their time is spent writing new queries or piping in more data vs. optimizing heavy/deteriorating queries.
Data cloud cost optimization is also in the best interest of the data warehouse and lakehouse vendors. Yes, of course they want consumption to increase, but waste creates churn. They would rather encourage increased consumption from advanced use cases like data applications that create customer value and therefore increased retention. They aren’t in this for the short-term.
That’s why you are seeing cost of ownership become a bigger part of the discussion, as it was in my conversation at a recent conference session with Databricks CEO Ali Ghodsi. You are also seeing all of the other major players–BigQuery, RedShift, Snowflake–highlight best practices and features around optimization.
This increase in time spent will likely come both from additional headcount, which will be more directly tied to ROI and more easily justified as hires come under increased scrutiny (a survey from the FinOps foundation forecasts an average growth of 5 to 7 FinOps dedicated employees). Time allocation will also likely shift within current members of the data team as they adopt more processes and technologies to become efficient in other areas like data reliability.
https://cdn.embedly.com/widgets/media.html?src=https%3A%2F%2Fwww.youtube.com%2Fembed%2FCN7UAW7PlQA%3Ffeature%3Doembed&display_name=YouTube&url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DCN7UAW7PlQA&image=https%3A%2F%2Fi.ytimg.com%2Fvi%2FCN7UAW7PlQA%2Fhqdefault.jpg&key=a19fcc184b9711e1b4764040d3dc5c07&type=text%2Fhtml&schema=youtubeMore trend talk from my colleague Shane Murray.
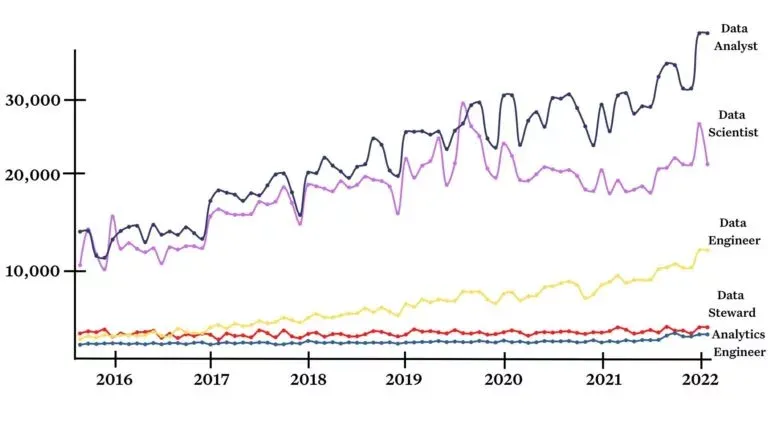
Prediction #2: Data team roles will further specialize
Currently, data team roles are segmented primarily by data processing stage:
- Data engineers pipe the data in,
- Analytical engineers clean it up, and
- Data analysts/scientists visualize and glean insights from it.
These roles aren’t going anywhere, but I think there will be additional segmentation by business value or objective:
- Data reliability engineers will ensure data quality
- Data product managers will boost adoption and monetization
- DataOps engineers will focus on governance and efficiency
- Data architects will focus on removing silos and longer-term investments
This would mirror our sister field of software engineering where the title of software engineer started to split into subfields like DevOps engineer or site reliability engineer. It’s a natural evolution as professions start to mature and become more complex.
Prediction #3: Data Gets Meshier, But Central Data Platforms Remain
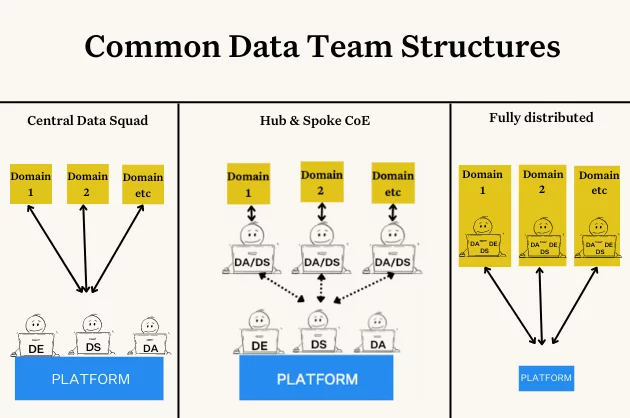
Predicting data teams will continue to transition toward a data mesh as originally outlined by Zhamak Dehgani is not necessarily a bold bet. Data mesh has been one of the hottest concepts among data teams for several years now.
However, I’ve seen more data teams making a pitstop on their journey that combines domain embedded teams and a center of excellence or platform team. For many teams this organizing principle gives them the best of both worlds: the agility and alignment of decentralized teams and the consistent standards of centralized teams.
I think some teams will continue on their data mesh journey and some will make this pitstop a permanent destination. They will adopt data mesh principles such as domain-first architectures, self-service, and treating data like a product–but they will retain a powerful central platform and data engineering SWAT team.
Prediction #4: Most machine learning models (>51%) will successfully make it to production
I believe we will see the average organization successfully deploy more machine learning models into production.
If you attended any tech conferences in 2022 (they came back!), you might think we are all living in ML nirvana; after all, the successful projects are often impactful and fun to highlight. But that obscures the fact that most ML projects fail before they ever see the light of day.
In October 2020, Gartner reported that only 53% of ML projects make it from prototype to production — and that’s at organizations with some level of AI experience. For companies still working to develop a data-driven culture, that number is likely far higher, with some failure-rate estimates soaring to 80% or more.
There are a lot of challenges, including:
- Misalignment between business needs and machine learning objectives,
- Machine learning training that doesn’t generalize,
- Testing and validation issues, and
- Deployment and serving hurdles.
The reason why I think the tide starts to turn for ML engineering teams is the combination of increased focus on data quality and the economic pressure to make ML more usable (of which more approachable interfaces like notebooks or data apps like Steamlit play a big part).
Prediction #5: Data contracts move to early stage adoption
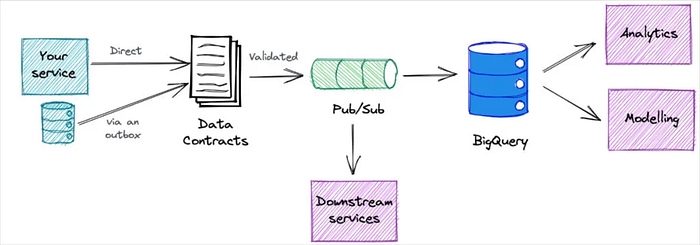
Anyone who follows data discussions on LinkedIn knows that data contracts have been among the most discussed topics of the year. There’s a reason why: they address one of the largest data quality issues data teams face.
Unexpected schema changes account for a large portion of data quality issues. More often than not, they are the result of an unwitting software engineer who has pushed an update to a service not knowing they are creating havoc in the data systems downstream.
However it’s important to note that given all the online chatter, data contracts are still very much in their infancy. The pioneers of this process–people like Chad Sanderson and Andrew Jones–have shown how it can move from concept to practice, but they are also very straight forward that it’s still a work in progress at their respective organizations.
I predict the energy and importance of this topic will accelerate its implementation from pioneers to early stage adopters in 2023. This will set the stage for what will be an inflection point in 2024 where it starts to cross the chasm into a mainstream best practice or begins to fade away.
Prediction #6: Data warehouses and data lakes use cases start to blur

Back as late as last week, at your data happy hour you might get away with saying, “data lakes are better for streaming, AI and more data science use cases whereas data warehouses are better for analytical use cases,” while others sagely nodded their heads.
Say that same sentence in 2023, and you will be met with nothing but scoffs and guffaws.
In the last year, data warehouses focused on streaming capabilities. Snowflake announced Snowpipe streaming and refactored their Kafka connector so that when data lands in Snowflake it is queryable immediately resulting in a 10x lower latency. Google announced Pub/Sub could now be streamed directly into the BigQuery making connecting streams into a data warehouse easier than ever.
At the same time, data lakes like databricks have added metadata and structure to stored data. Databricks announced Unity Catalog, a feature enabling teams to more easily add structure like metadata to their data assets.
New table formats have become an arm’s race with Snowflake announcing Apache Iceberg for streaming and Unistore hybrid transactional-analytical processing tables (HTAP) for transactional workloads while Databricks has emphasized its delta table format, which have both ACID and metadata properties.
A safer line for your 2023 happy hour is to bemoan the expectations of your business stakeholders–that’s a classic that never goes out of style.
Prediction #7: Teams achieve a faster time to resolution for data anomalies
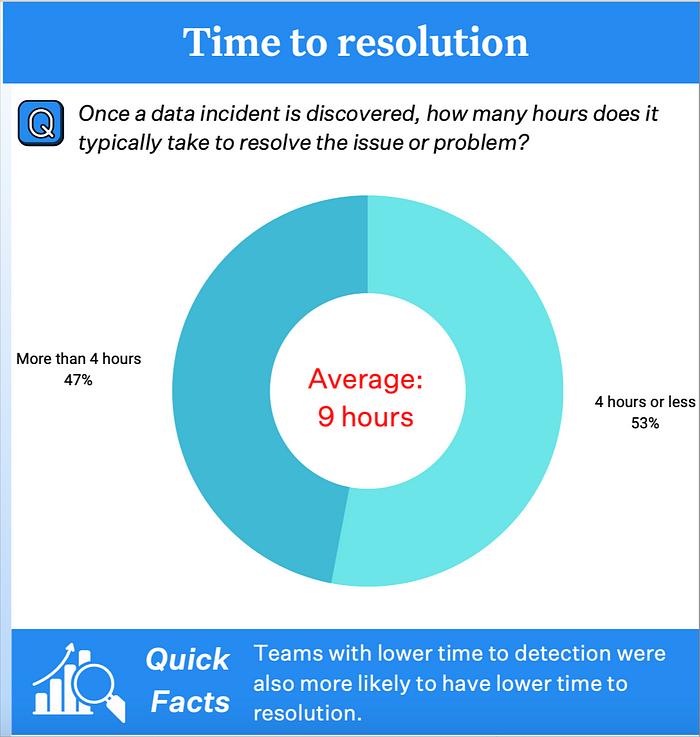
A 2022 survey by Wakefield research of more than 300 data professionals revealed respondents spent an average of 40% of their workday on data quality. That’s a lot.
Data downtime is a simple equation: number of incidents x (average time to detection + average time to resolution). The Wakefield survey also revealed organizations experience an average of 61 incidents per month with an average of 4 hours to detect and another 9 hours to resolve that incident.
In speaking with hundreds of data leaders this year, it’s my observation that many have lowered time to detection by moving from static hard-coded data testing to machine learning based data monitoring.
That’s exciting, as is the potential for new innovations in automatic root cause analysis. Features like segmentation analysis, query change detection, data lineage, and more can help narrow the possibilities of “why is the data wrong” from infinite to a handful of possibilities whether the issue be with systems, code, or the data itself.
2023: The year big data gets smaller and more manageable
As we conclude 2022, I’d describe data engineering as being in a unique moment in time where storage and compute limitations have largely been erased — big data can be as big as it wants to be. The pendulum will swing again as it always does, but it’s not likely to be in the next year.
As a result, next year’s hottest trends will be less about optimizing or scaling infrastructure, but instead processes for making this enlarged universe more organized, reliable, and accessible.
##
I might be wrong, but I’m on the record. Connect and let me know your thoughts and predictions for the next year.

Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
sure
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Your article helped me a lot, is there any more related content? Thanks!
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Your article helped me a lot, is there any more related content? Thanks!
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?