KPIs & Data Team
As analytics professionals, we deal in data: serving ad-hoc reports on a minute’s notice, pulling queries for executives, and generally forecasting company performance across a variety of metrics. But how can we be truly successful if we don’t measure our own performance, too?

In this article, we discuss six important steps to setting goals for our own data teams, from taking time for exploration to avoiding vanity stats while maintaining a constant pulse on the *actual* needs of the business.
I recently had a great conversation with Boris Jabes, CEO and co-founder at Census, on The Sequel Show. We touched on all sorts of data-related topics, from why data downtime happens to centralized vs decentralized data teams to how the Kingdom of Bhutan measures citizen happiness like most countries measure GDP. But when our conversation meandered to data KPIs (key performance indicators), things got really interesting.
Boris and I set off into KPI-land when I shared one of my favorite quotes from Dwight D. Eisenhower: “Plans are worthless, but planning is everything.”
We’ve both seen Ike’s wisdom borne out at so many companies. The very act of planning is inherently valuable, even if the plan you come up with will (and should) change.
The same goes for data leaders and KPIs. You should develop metrics to measure your performance against because the process of aligning teams, defining success, and rallying around a shared goal can make a tremendous impact. Obsessing over the ideal goal or measurement tactic isn’t the point — and can actually get in the way of meaningful progress. The important thing is to start working with your data in a formalized way towards a concrete goal.
With that context in mind, here’s a recap of the six steps we covered that help data leaders set useful goals and measure performance.
Understand what your customers really want and need
As you set out to determine what your data team’s goals will be (and how you’ll crush them), start by understanding what your customers want and need. At Monte Carlo, our north star has been “what do our customers care about, and how do we solve it as fast as possible?” And answering those questions takes alignment across teams.
For example, if you agree with engineering, product, and marketing that onboarding is a pain point, you can decide to build goals and KPIs around making it easier for new customers to get started. While you could choose to spend a few years architecting an entirely new process, you’ll see more immediate results by making small improvements that you can test and iterate as you get feedback from customers.
By aligning the company around the shared goal of reducing new tool onboarding from five days to three days, for instance, you can begin to address the problem holistically: your data team gathers metrics on usage and helps build A/B tests, while your engineering team modifies the product, and your marketing team creates nurture campaigns. This is what it looks like to define and execute against a company-wide goal.
Just make sure you’re aligning around a concrete metric that means something tangible to the business. Skip vanity metrics and look at numbers that are tied to outcomes like annual recurring revenue, customer churn, financial performance, or something else that’s concrete and measurable.
For Monte Carlo, every team is oriented around metrics that largely relate to customer happiness, like revenue, NPS, and customer satisfaction. By placing customer happiness at the center of our KPIs, we keep every team working toward a common purpose — which is the entire point of setting goals.

Make a plan, but revisit it often
While your goal is important, remember what Ike said: planning is everything. The planning process is crucial because it forces your teams and executives to undertake scenario planning. You can’t do everything on your wishlist, especially at a startup, so planning forces a discussion about prioritization that can lead to key realizations about hiring and resourcing.
For a data team, an example of this might be setting three OKRs every quarter that will truly move the needle that align with your company’s bottom line. As in the case of a tech company like Airbnb or Shopify, an OKR might be something ambitious like shipping an experimentation platform or launching a new self-serve feature for the in-house data platforms. Smaller companies or startups might be more likely to align these milestones around improving organizational maturity (measurable, perhaps, by how many consumers leverage your dashboards) or more accurate reporting. Regardless, it’s important to stay focused on what will actually matter for your stakeholders, versus vanity metrics like number of new reports or models.
A note of caution: it’s easy to spend way too much time on planning. We don’t need to get an A+ in building OKRs. We need to get an A+ in building a business.
So keep your primary goal at the forefront and stay flexible by revisiting your plan often. You may not know what the right metric is, and you may undershoot or overshoot your KPIs, but the act of coming together and learning throughout the process is so valuable. Give yourself the freedom to reorient your team and find a new path to achieve your goal if the first metric you tried isn’t getting the job done.
Prioritize KPIs based on your business goals
If it’s not the right goal for your business right now, then it’s not the right KPI.
I’ve seen across organizations of all sizes that people can waste time on creating very detailed OKR plans that will have to shift, no matter what. Teams can get obsessed with systems rather than goals. For example, some engineers may become obsessed with creating beautiful code that will scale to millions of users — but if their company only has hundreds of users, that’s not going to make an impact.
For instance, if your KPI was focused on building an experimentation platform for the entire company but only a few teams will need it next quarter, keep it small and targeted. This means incorporating their feedback instead of trying to boil the ocean by solving for use cases that don’t exist yet. A second example might be setting and measuring SLAs for certain data sets (i.e., ones relating to customer engagement or financial health) instead of rolling them out across all data.
Give your team the tools they need to ruthlessly prioritize their work. Boris and I have both seen young data teams that don’t yet have ticketing systems or intake processes in place that enable prioritization — which is essential to meeting any goal. So implement a structure that creates a sense of urgency around the most important problems you need your team to focus on and solve.
Set goals based on solving problems, not adopting new technologies
Similarly, data teams may become too focused on infrastructure and tools — because our industry is growing so quickly and tools are improving every day. But if your team’s desire to adopt a new tool isn’t rooted in solving a meaningful business problem, then you may be at risk of “shiny new toy” syndrome.
All too often I’ve seen teams at some of the sharpest companies get lost in the excitement of building data platforms for the sake of building data platforms, or choosing to work on projects that they think will look impressive to their CTOs, instead of tackling real business problems. If you want to move your data team to Kubernetes simply because it’s trending on Reddit, I’d encourage you to reassess. Same goes for building tools from scratch instead of investing in existing open source or SaaS options. If your use case is similar to the vast majority of companies, it probably doesn’t make sense to reinvent the wheel.
Especially if your data team is newer and less mature than other teams within the organization (which is very common at this moment in time), be careful to focus on goals that deliver clear value to the business. Understand that a smaller team of two or three people can only accomplish so much, and consider what kinds of questions your company needs you to answer.
If you’re still working on basics like…
- How many customers do we have?
- What’s our annual recurring revenue?
- What’s our churn rate?
…then it’s not the time to focus on setting up an advanced, complex data infrastructure. It’s time to deliver the fundamental information your company needs at this moment.
Dedicate time to freeform exploration
While you want to align KPIs and work toward shared goals with other teams, the truth is that sometimes the rest of the business doesn’t know what to ask of your data org. That’s why you need to give your team time to explore.
Think of it this way: all humans need time to relax and play to process information most effectively. That’s why you always seem to have your best ideas in the shower.
Similarly, your team members can come to new and exciting conclusions when they’re given time to explore the data for fun. They can apply their talents to looking for patterns that no one has requested, and have the space to uncover new discoveries. This freeform exploration can lead to game-changing innovations that no business stakeholder would have imagined were possible.
For better or worse, one element of the data analytics workflow that facilitates this is ad-hoc analysis, the bane of many a data engineer’s or analyst’s existence. Receiving urgent pings early in the morning or late at night about querying a data set aren’t usually the definition of a good time, but sometimes these unexpected projects (particularly if they’re tied to one of the business’ larger KPIs) can reap benefits beyond the output of the query. Without these impromptu requests, it can be harder to know what’s most pressing for your stakeholders, particularly as plans shift. Note: these ad-hoc assignments don’t replace regular planning and stakeholder syncs, but they can force creativity and exploration where there previously wasn’t.
As a bonus, freeform exploration gives passionate data pros the chance to find more delight in doing what they love, which helps keep your most valuable team members engaged and satisfied in their work.
Enable effective knowledge transfers
We talk a lot at Monte Carlo about learning and applying best practices from our counterparts in engineering. That’s where our inspiration for data observability comes from, and it’s where we should look to learn about improving the practice of knowledge transfer.
Knowledge transfer is part of the job for engineers. After building a product, an engineer has to hand off responsibility for maintaining their code and solving their bugs to other developers. If they insisted on keeping ownership of their code, they’d spend all their time on maintenance and bug fixes, and never build anything new or take on a new role. So they’ve developed best practices around documentation, like leaving a comment that describes when issues occur and how they’ve been fixed.
For data professionals, the same principles apply — but newer teams may be lacking the best practices like ticketing systems and documentation that engineers have proven out. To help your data team meet their KPIs and avoid lost productivity due to poor knowledge transfer, start setting those tools and systems into place.
One popular tool for knowledge sharing? The aptly named knowledge graph. Knowledge graphs are a paradigm often leveraged by SaaS data solutions that automatically represents data as nodes in a graph, drawing connections via logic and metadata. Knowledge graph-based tools, like lineage, are often automated to help data teams save time and resources when it comes to generating quick documentation about the relationships between and about data across the organization.
And while handoffs can be painful enough within a small data team, communicating across departments can be really challenging. Formalizing service-level agreements (SLAs) and service-level indicators (SLIs), and putting together implicit and explicit contracts between teams can help everyone stay aligned on priorities as you work to meet your goals.
Your SLIs will depend on your specific use case, but here are a few metrics used to measure data trust, a common KPI:
- The number of data incidents for a particular data asset (N). Although this may be beyond your control, given that you likely rely on external data sources, it’s still an important driver of data downtime and usually worth measuring.
- Time-to-detection (TTD): When an issue arises, this metric quantifies how quickly your team is alerted. If you don’t have proper detection and alerting methods in place, this could be measured in weeks or even months. “Silent errors” made by bad data can result in costly decisions, with repercussions for both your company and your customers.
- Time-to-resolution (TTR): When your team is alerted to an issue, this measures how quickly you were able to resolve it.
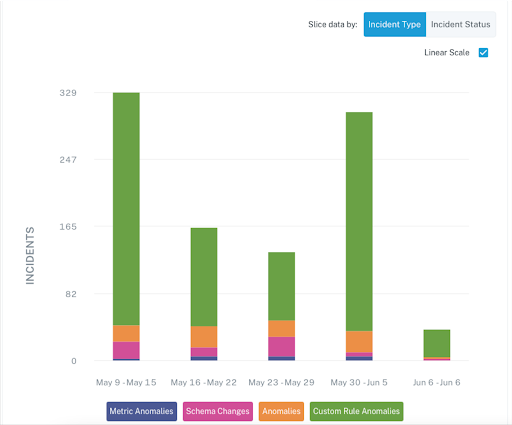
A dashboard to track the number of data incidents can help you improve data reliability over time. Image courtesy of author.
If you want to take these a step further, try generating a data KPI dashboard for these metrics.
Bottom line: start learning by doing with data KPIs
Data teams can use KPIs to set strategies and achieve goals, but ultimately, the most important step is to get started.
Your metrics will never be set in stone. Be prepared to learn quickly when some goal is wasting your time, and move on even quicker. If you begin by collaborating with other departments and aligning your own team around a shared goal, you will see an impact — especially if you’re a competitive data leader like me, who loves bringing a team together to crush our numbers as fast as possible.
And as you begin to focus on important business goals, you’ll find more value in creating repeatable processes, automating rote tasks, and moving away from reactively responding to data fire drills.
Want to learn more about setting your data team up for success? Get insights from the experts at PagerDuty, Uber, and other data-first companies in The Modern Data Leader’s Playbook, or follow me on LinkedIn.

Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Your article helped me a lot, is there any more related content? Thanks!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Your article helped me a lot, is there any more related content? Thanks!
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.